Mind Lab Toolkit (MinT)
Building the Infrastructure for Experiential Intelligence
MinT stands for the Mind Lab Toolkit. We are building the reinforcement learning infrastructure necessary for agents and models to “learn from real experience.”
Our mission is to provide a pragmatic, transparent, and reusable foundation for Experiential Intelligence—ensuring that the complexity of the real world, with all its noise and nuance, becomes a resource for learning rather than a barrier to development.
What is MinT?
MinT focuses on the engineering and algorithmic realization of Reinforcement Learning (RL) across multiple models and tasks. We place specific emphasis on making LoRA RL (Low-Rank Adaptation Reinforcement Learning) simple, stable, and efficient for both mainstream and frontier models.
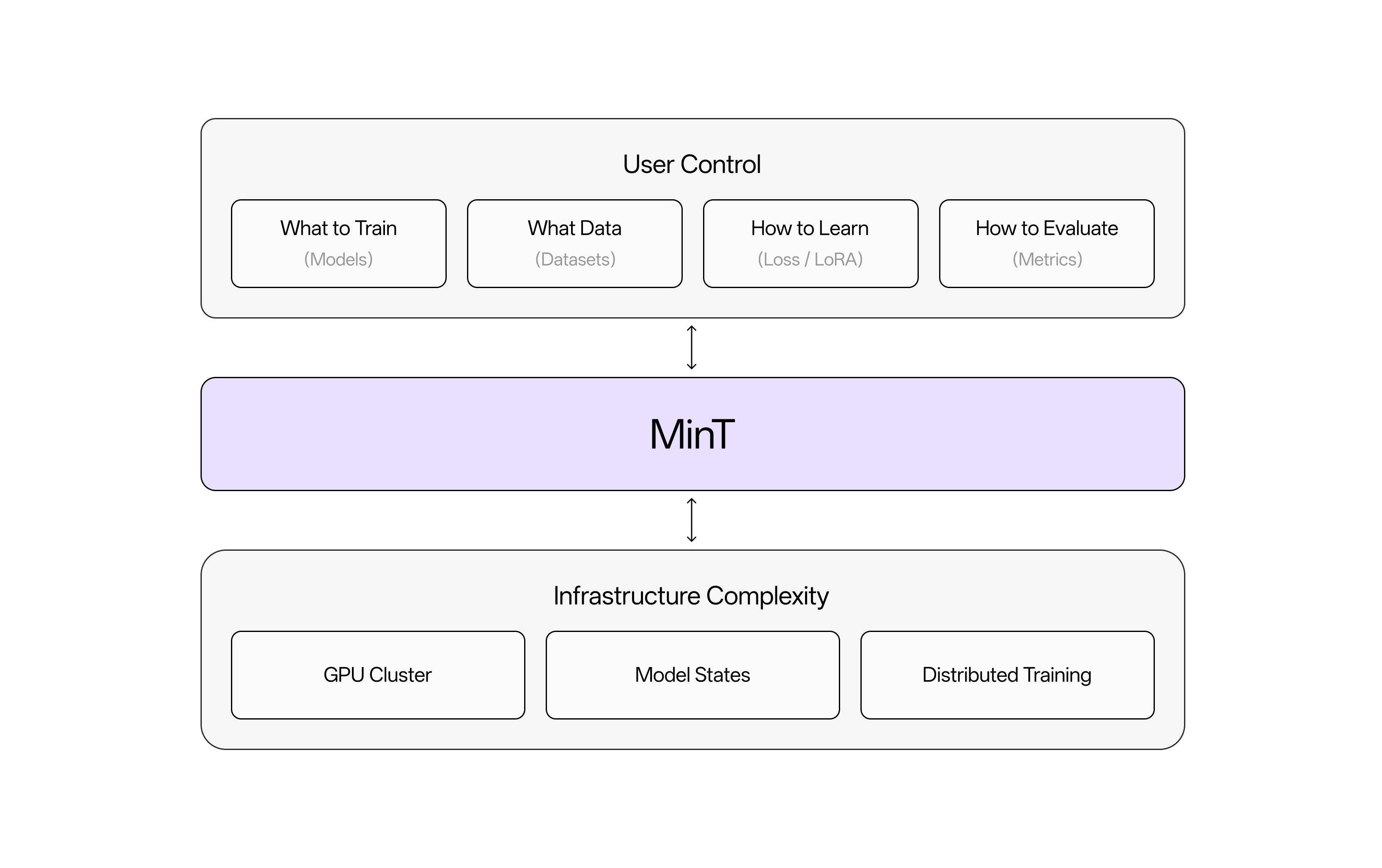
MinT abstracts away infrastructure complexity—GPU clusters, model states, distributed training—so you can focus on what matters: choosing models, preparing data, defining learning objectives, and evaluating results.
Key Features
- Model Support: Kimi, K2, DeepSeek, Qwen, Pi0, and others—ensuring a rapid closed loop from inference to training
- Algorithm Support: Robust training pipeline centered on RLHF/GRPO and general policy optimization
- Frictionless Migration: Initial API compatibility with ThinkingMachines Tinker, designed as a familiar drop-in upgrade
- Scaled Agentic RL: Capture and utilize experience at scale across wider task distributions, longer interaction horizons, and richer environmental constraints
Core Capabilities
- LoRA fine-tuning for efficient training of large models
- Distributed data collection and rolling training
- Support for vision-language models (Qwen3-VL)
- Weight management and model publishing
- Online evaluation on standard CPU clusters
Who We Build For
For Builders: Focus on understanding your problem and designing mechanisms—let MinT handle the infrastructure. We open up the workflows, evaluation schemes, and training infrastructure we use in real business scenarios.
For Researchers: Reduce engineering friction in RL research with standardized logging, reproducible evaluation, portable workflows, and interpretable training data lineage.
Core API Functions
forward_backward: Computes and accumulates gradientsoptim_step: Updates model parameterssample: Generates outputs from trained models- Weight/optimizer state persistence functions
Values
We insist on real experience as the primary constraint. We insist on transparent engineering. We insist on delivering reusable workflows to the community.